On Sep 25, 2023, OpenAI introduced GPT-4V(ision), a multimodal language model that allowed users to analyze image inputs. The release was accompanied by the GPT-4V system card, which contained virtually no information about the engineering process used to create the system. Moreover, OpenAI did not release any source code or model files that would allow researchers to further probe and evaluate the model. This lack of transparency presents a serious evaluation and explainiability risk.
Luckily, open source AI advocate Hugging Face released their own multimodal language model, IDEFICS, on August 22, 2023, a full month before OpenAI's release. IDEFICS is fully open source, with all code, model weights, model files, and training data made available for everyone.
Nomic worked together with Hugging Face to build a public map of a ~10% sample of the IDEFICS training set. This map was used for model evaluation, and resulted in the discovery of several errors and systematic failure modes that were previously unknown. In this blog post, we will describe how we used the map to discover these model behaviors, and remark on the importance of open data and accessible interfaces for model explainability.
Hugging Face provided model loss metadata to Atlas along with the IDEFICS embedding of each data point. This enabled us to slice and dice the IDEFICS latent space by how well the model performs on predicting the next token on a particular datum. We found that model loss varies continuously across latent space, and that data inducing particularly high and low loss tend to be concentrated in distinct semantic areas.
We can investigate the regions where the high loss data concentrates in latent space to learn more about what errors IDEFICS may be making. In some cases, we find that the data itself has a systematic error, and that it should be removed from the modeling pipeline. In other cases, we find that IDEFICS poorly predicts the underlying data, indicating a systematic model failure mode.
One region of high loss is an island in the southeast corner of the map. This cluster contains web pages whose text is gramatically reasonable, but senseless. For instance, one datum in the island reads "Download to handle the halter. The racing is out pitted. Geographical estimate can lead from the empty..." We came up with several hypotheses regarding the origin of these pages: they could be misextracted web text, the result of low budget content mills, or poor automatic translations. Regardless of their origin, it is clear that we should not include them in subsequent model trains. We can easily mark the entire population for removal from the train set using Atlas' tagging feature, as show below:
As part of the map creation process, Atlas automatically performs topic modeling and topic annotation on user supplied data. The resulting topic annotations can be displayed on the map, which helps users orient themselves to the semantic interpretations of different latent space regions.
Using Atlas topics for model evaluation flips the standard evaluation paradigm. In the standard model evaluation framework, users examine the performance of a model on several predefined benchmarks. Unfortunately, benchmark selection requires evaluators to guess what kinds of tasks their model might fail on a priori. Using Atlas, we can instead discover the systematic failure modes that a model exhibits. These failure modes are often outside the scope of standard benchmarks, and thus, could lurk undiscovered without explicit latent space analysis.
Empirically, several the topics Atlas extracted correlated with high loss regions in the IDEFICS map. Take, for instance, the poetry topic:
We theorize that the distinct subversion of common linguistic patterns in poetry is one reason that IDEFICS performs poorly when modeling poetic text.
We found concentrations of high loss data in a wide variety of topics beyond poetry, including fishing, biology, and government:
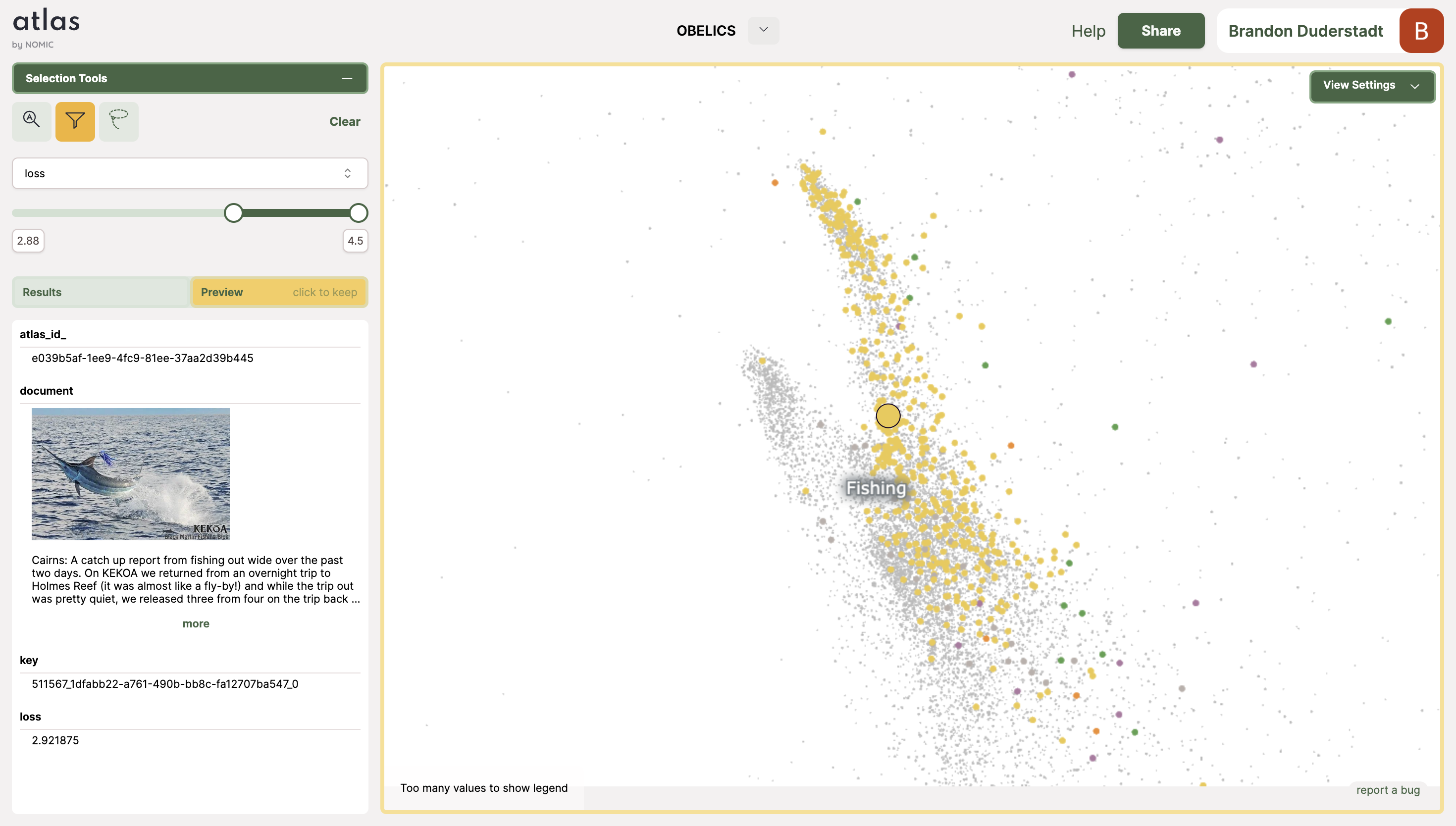
The fishing topic consists of two peninsulas. IDEFICS seems to have systematically high loss in the eastern peninsula, but not in the western one. This indicates that there is a categorical distinction between the data in the peninsulas that correlates with high loss.
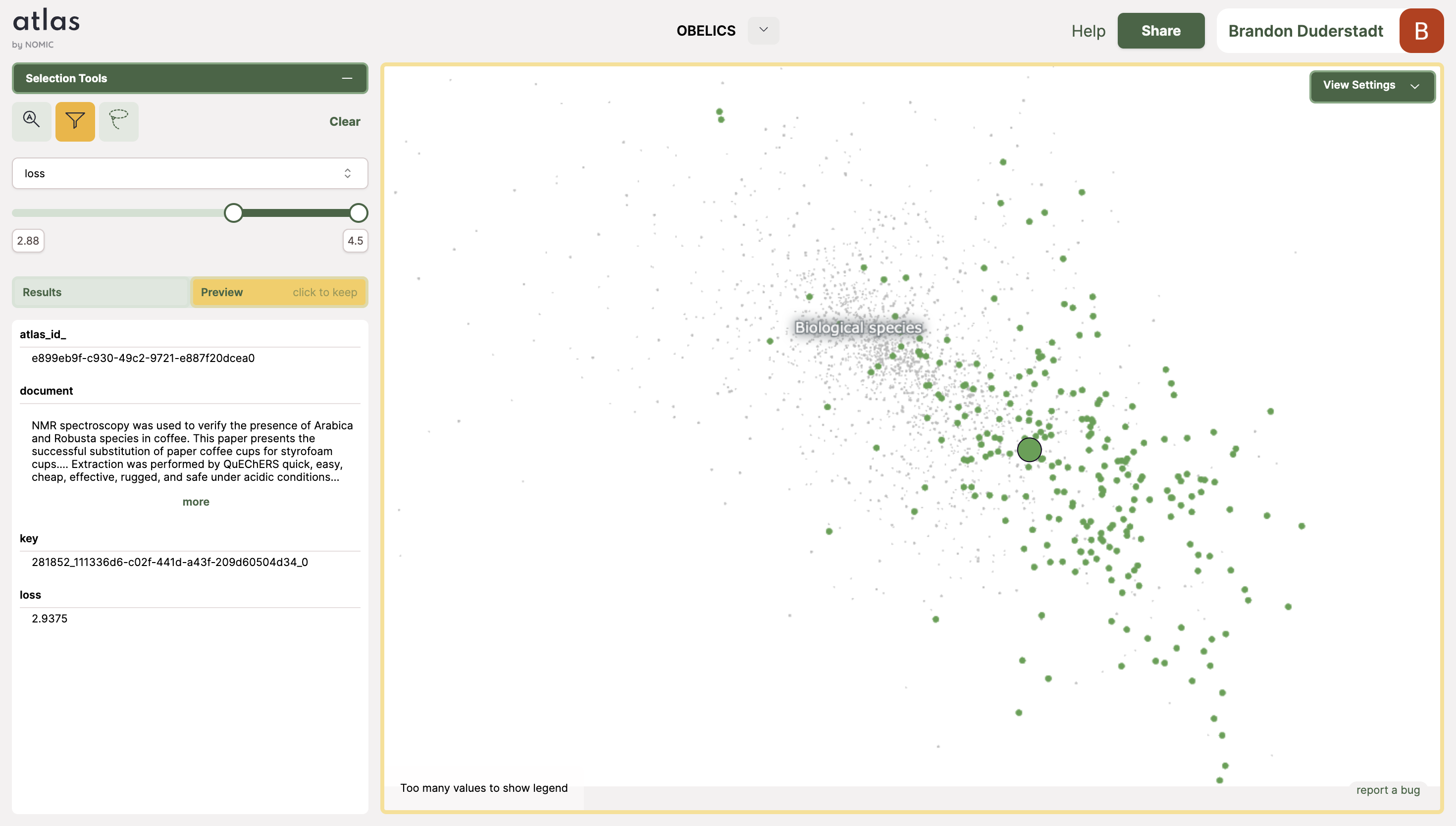
The biological species topic consists of a singular island. IDEFICS gets progressively worse at modeling the data in this topic as it progresses to the southeast. This indicates that there is a continuous variation along the major axis of the island that correlates with high loss.
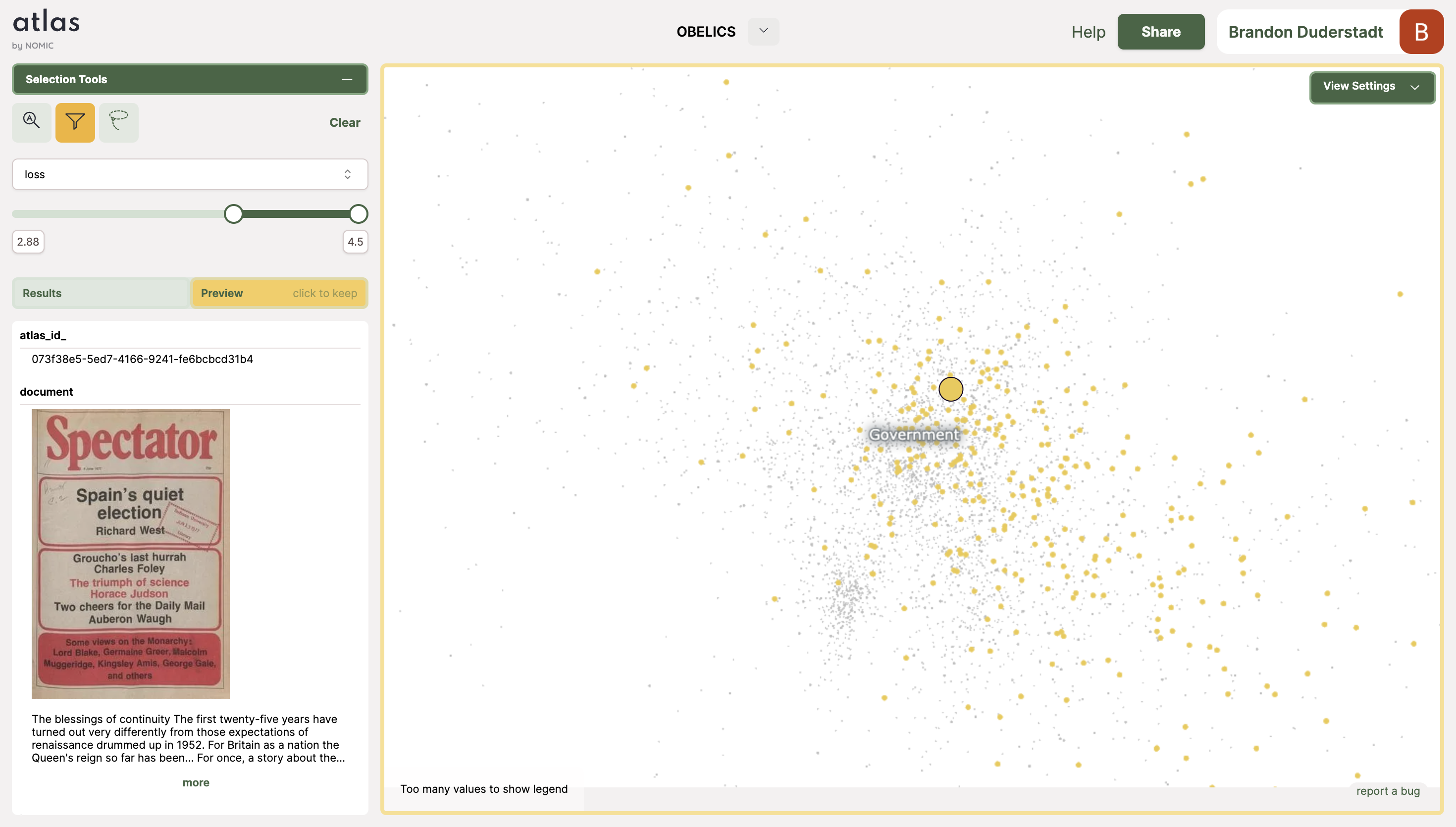
The government topic also consists of a singular island. IDEFICS gets high loss on data that is speckled uniformly around this island. This indicates that there may not be a semantically interpretable correlate with high loss data in this topic.
Similarly to the high loss data, there are also concentrated regions of low loss data in the latent space. We can investigate these regions to learn more about populations of data that the IDEFICS does particularly well at modeling. We again find populations of data with systematic errors which should be removed from the modeling pipeline. We also discover several topics of concentrated low loss data. Some of these topics contain repeated text that the model is likely memorizing, while others contain text that could lead to viewpoint amplification.
One of the regions of particularly low loss in IDEFICS data is this red peninsula of documents containing the phrase "END_OF_DOCUMENT_TOKEN_TO_BE_REPLACED."
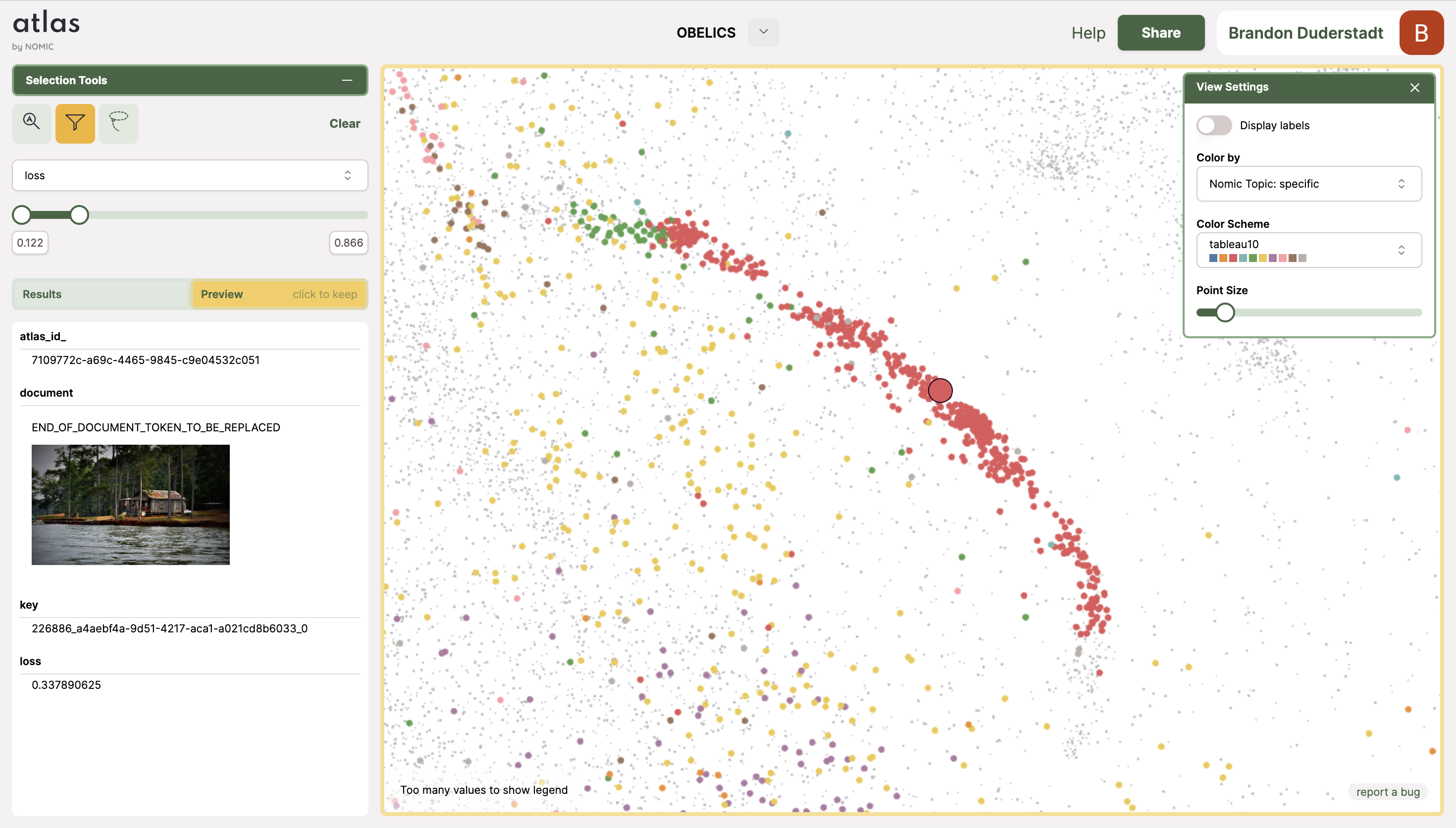
This population of data was clearly intended for further preprocessing, but managed to slip through the cracks. This is unsurprising; the task of preprocessing the massive datasets used to train AI models is an intense undertaking, and is often distributed amongst many individuals working in tandem for months. As such, preprocessing errors inevitably happen to even the best of teams, and it's important to institute systems that can surface and correct these errors when they do occur.
Like the high loss topics, Atlas also extracted topics that contained an outsized population of low loss data in them.
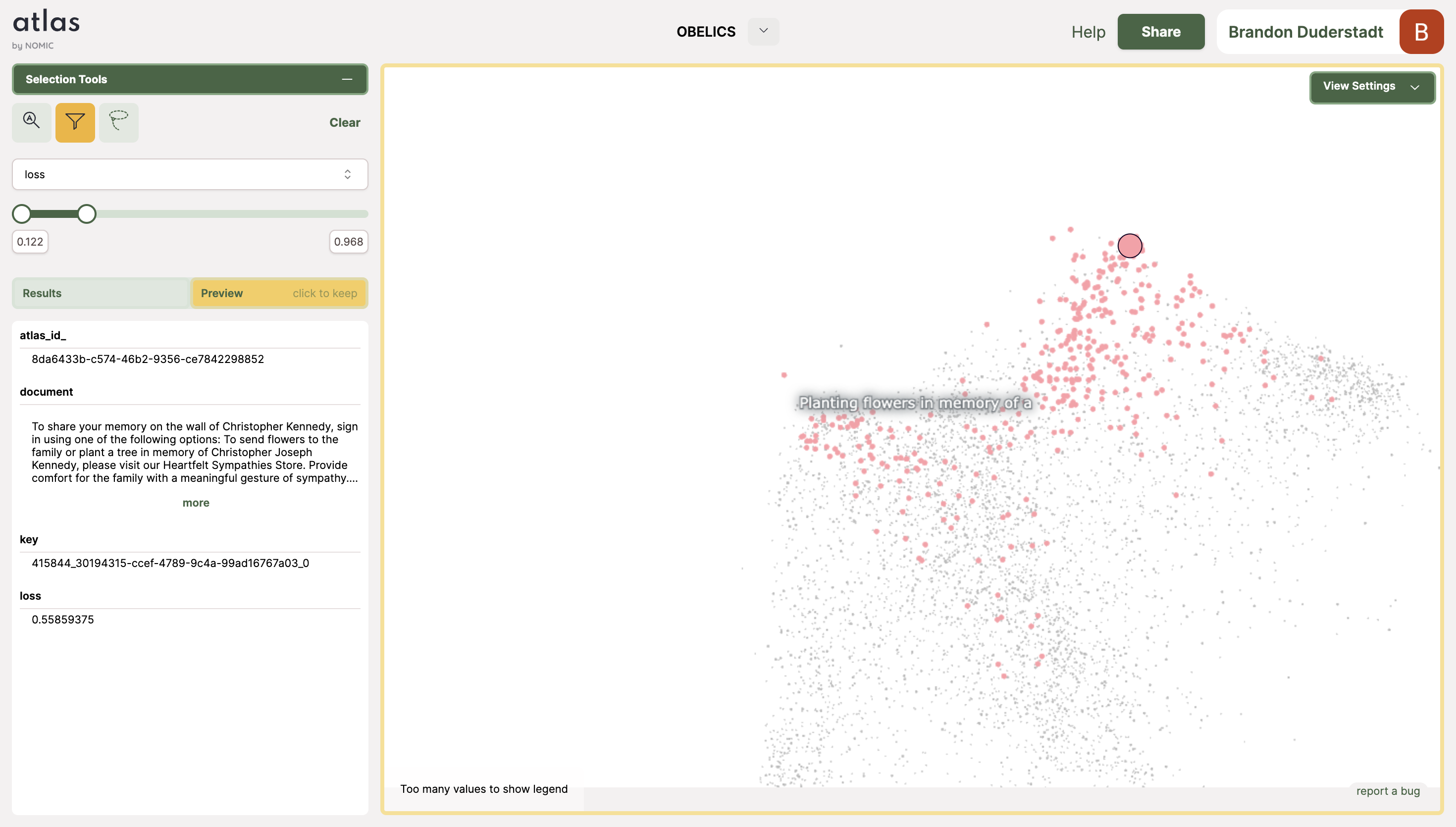
An example of templated language that is replicated throughout the training dataset.
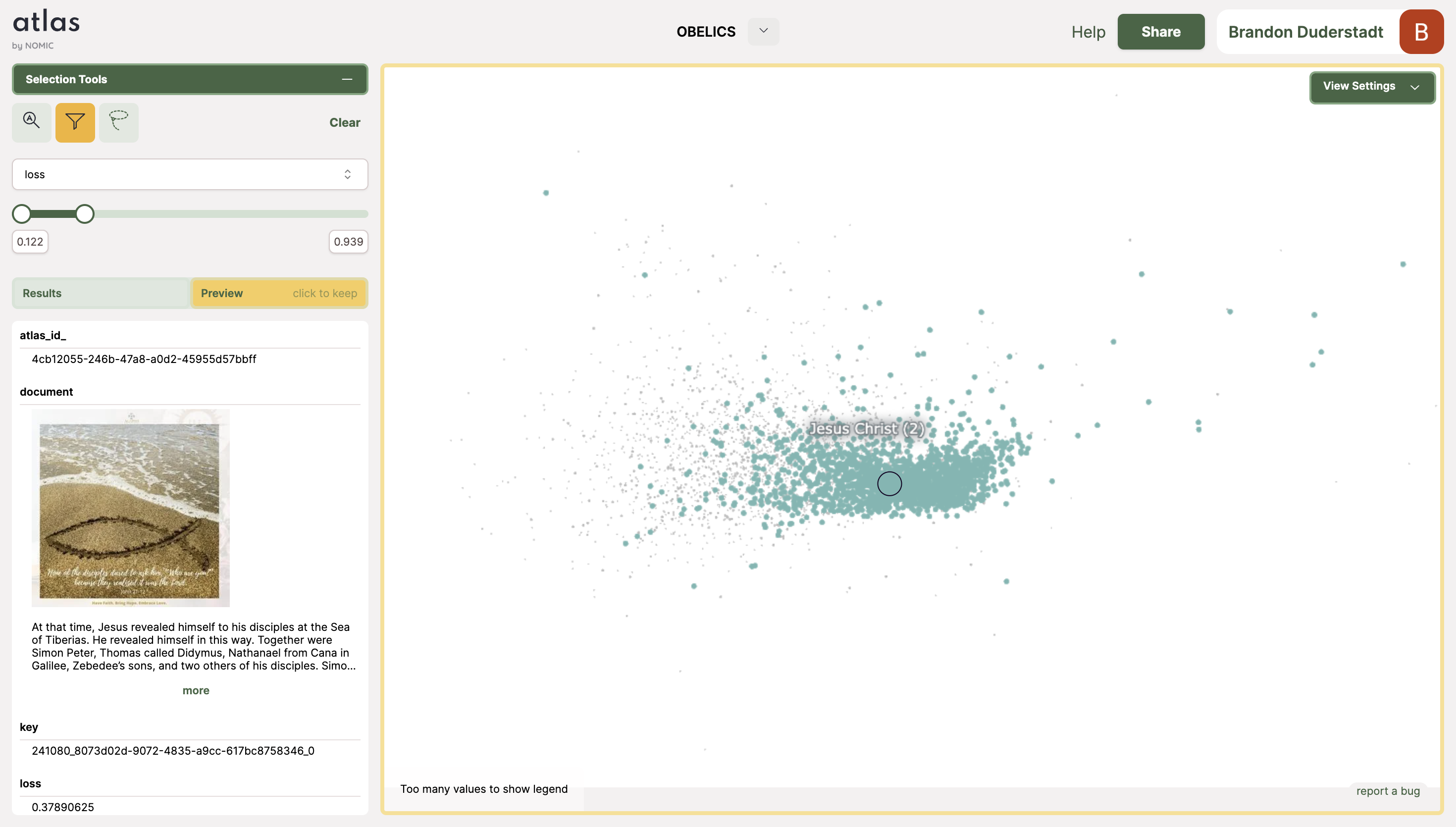
Data in the Jesus Christ (2) topic achieves systematically low loss, potentially biasing the model towards producing Christiocentric language.
In this post, we've shown how to use Atlas to evaluate IDEFICS, Hugging Face's multimodal model. Using Atlas, we were able to identify several data errors, systematic model failure modes, and potential model biases. You can sign up for Atlas here to begin evaluating your own models.
We emphasize that the reason we were able to uncover these errors is because of Hugging Face's commitment to open source and open science. It is clear that AI is going to revolutionize all aspects of human life. It is critical that models, datasets, and training methodologies remain both open and accessible. It is only through broad participation in the model creation process that we can hope to build models that are beneficial for everyone. We encourage you to sign Mozilla's Joint Statement on AI Safety and Openness to help support the effort to keep AI open.
